Cadastre-se agora para um orçamento mais personalizado!






























![]() This post was also authored by Min-yi Shen and Martin Lee.
This post was also authored by Min-yi Shen and Martin Lee.
Security is all about probability. There is a certain probability that something bad will happen to your networks or your systems over the next 24 hours. Hoping that nothing bad will happen is unlikely to change that probability. Investing in security solutions will probably reduce the chance of something bad happening, but by how much? And where should resources be most profitably directed?
Cyber security is a complex environment with many unknowns and interdependencies. TRAC data scientists research this environment to try and understand how different variables affect security. Bayesian graph models are one of our most useful tools for understanding probabilities in security and to explore how the likelihood of outcomes can be changed.
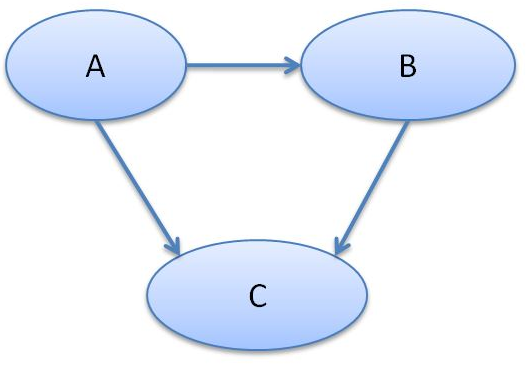 Figure 1 -A Simple Bayesian Network
Figure 1 -A Simple Bayesian NetworkThis example graph shows that C is affected by both A and B, whereas B is only affected by A. This notation of nodes and arrows is particularly useful to describe complex outcomes.
We can apply this theoretical representation to a real world scenario:
 Figure 2 -"System Crash" Bayesian Network
Figure 2 -"System Crash" Bayesian Network
A lightning strike during stormy weather hits a power line and causes a power failure. This in turn may cause the operating system to malfunction, causing a system crash. Alternatively a large power spike may cause a hardware failure that may also result in a system crash. But a system crash can also happen without stormy weather. Malware may interfere with the operating system or directly cause the system to crash.
The directed graph is useful because we can quickly deduce which variables are independent from other variables. We can see that a computer crash can be the result of a malware infection, an operating system failure, and/or hardware failure. We can also see that malware infection is independent of the stormy weather. In other words, you can get malware regardless of the weather outside.
We can also make operational decisions from such a graph. If the weather outside is stormy, we are at heightened risk for a system crash. Hence we may wish to change our security activities. Equally, we can also deduce that if we are aware of a power failure, we are in danger of experiencing a system crash no matter what the weather.
Once we have constructed such a graph we can begin to collect metrics and assign probabilities to the various outcomes on the graph. We can use the power of Bayesian network analysis to calculate the likelihood of outcomes. For example, let's say the probability of experiencing a system failure during stormy weather is 2.37%, or 2.27% if the weather is not stormy. From this, and using the probability of stormy weather, I can calculate the most likely scenario for computer infection: a malware infection and no storm (69.3%) compared with no malware infection and a storm (2.98%).
Real world examples can be daunting for data scientists and applied researchers. We are usually faced with a scenario where there is only partial data, and no obvious network structure. Nevertheless, we can apply probabilistic reasoning to construct such a network and deduce the outcome probabilities. Applying model parameter estimation using techniques popularized by R.A. Fisher, such as the maximum likelihood, allows us to estimate the maximum value for probabilities, but only if we are able to observe enough outcomes.
Observing and counting enough outcomes to make these kinds of conclusions has been a major challenge to data scientists. However, the advent of modern big data platforms such as Hadoop makes searching for, and counting, the events that we are interested in so much easier. Armed with these tools we are able to construct and populate real world models of the cyber security environment and begin to make conclusions about what variables affect this environment. And most importantly, we can begin to measure and make predictions about how to make the Internet a safer place.
Min-yi Shenstudied theoretical chemistry at the University of Chicago, spending four years simulating the dynamics of protein folding with his own accelerated 1/sqrt(x) function, which takes up 80% of the CPU time in simulations. He subsequently moved to UCSF as a postdoc, building a statistical classifier for protein structure models, and spent a summer in Harvard with the future Nobel Laureate Martin Karplus. He then left academia and joined Applied Biosystems to help developing their next-generation DNA sequencer. He brought his prior experience with data analysis when he joined Cisco security in 2011, where he worked as a data scientist before this term was conceived.
 Tags quentes :
Segurança
TRAC
probability
Tags quentes :
Segurança
TRAC
probability
Cadastre-se agora para Ações Semanais de Promoção
100% free, Unsubscribe any time!
Add 1: Room 605 6/F FA YUEN Commercial Building, 75-77 FA YUEN Street, Mongkok KL, HongKong Add 2: Room 405, Building E, MeiDu Building, Gong Shu District, Hangzhou City, Zhejiang Province, China
Whatsapp/Tel: +8618057156223 Tel: 0086 571 86729517 Tel em HK: 00852 66181601
Email: [email protected]
 English
English Pусский
Pусский Français
Français Español
Español Português
Português

