Cadastre-se agora para um orçamento mais personalizado!






















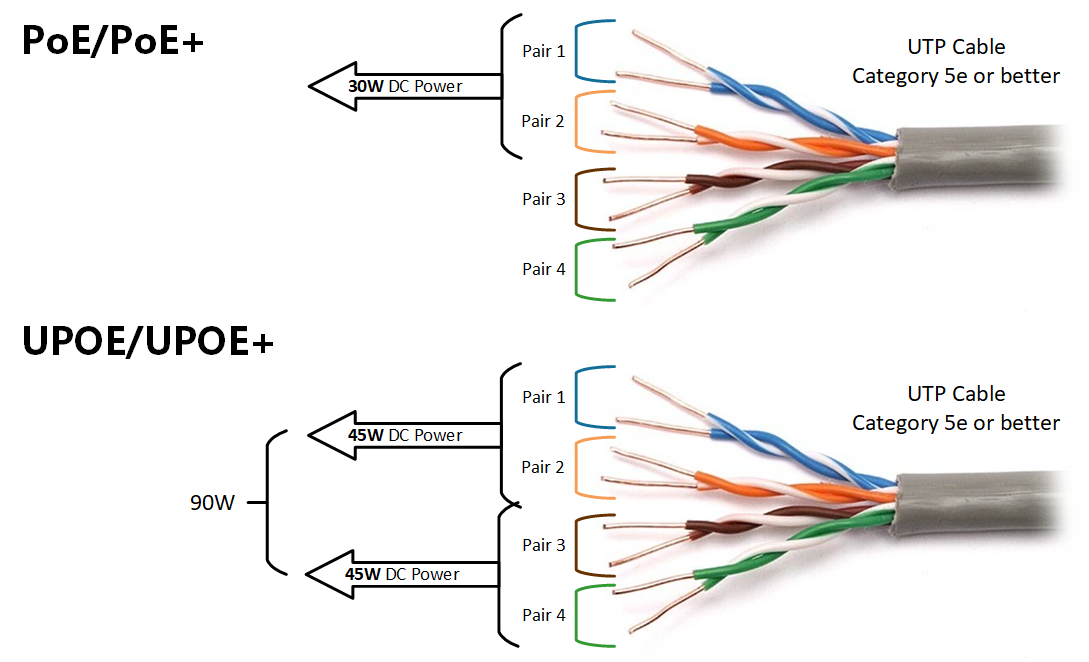
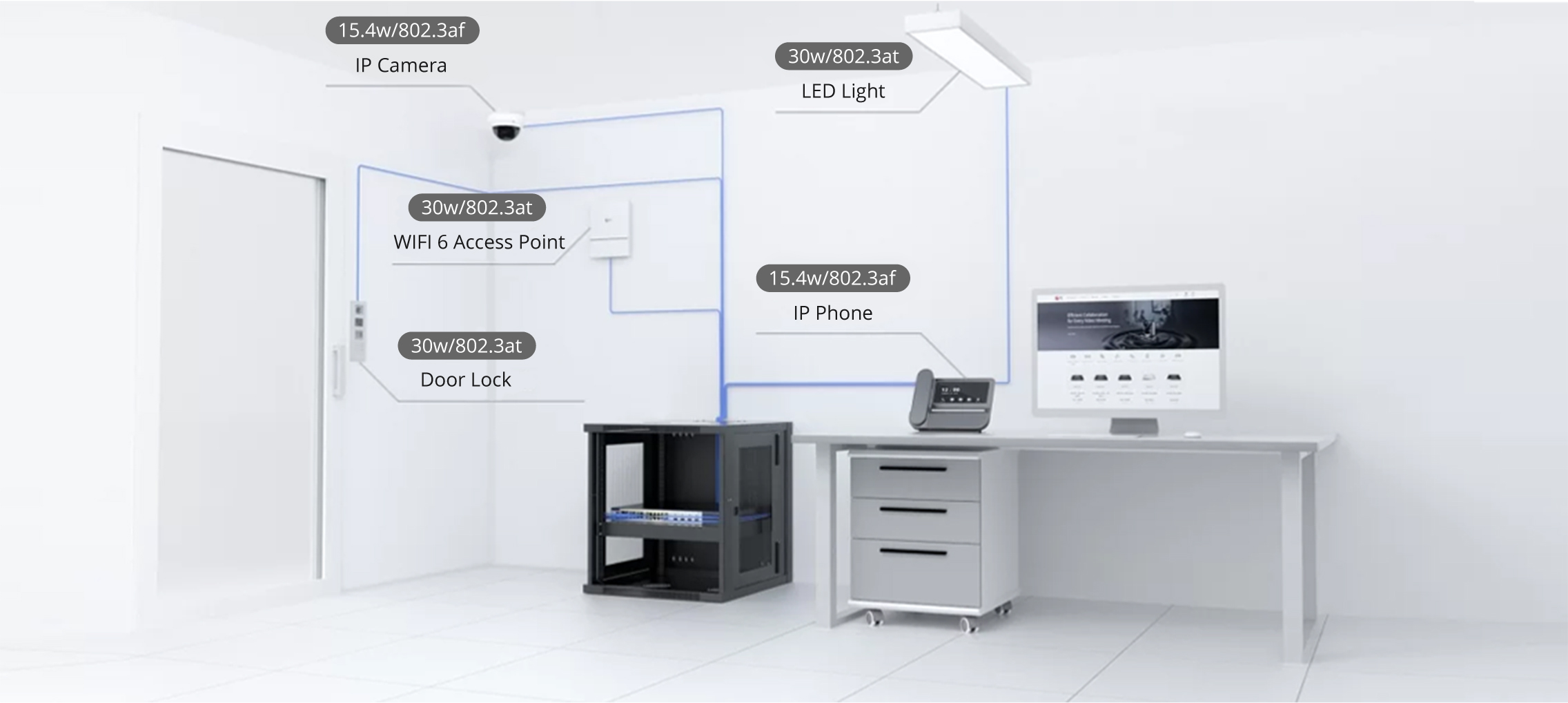






Meta announced a series of artificial intelligence (AI) models that significantly expand the capabilities of speech recognition and generation technology in an attempt to address the problem of endangered languages and multilingualism in the digital sphere. These models, called Massively Multilingual Speech (MMS) models, can now handle over 1,100 languages, compared to the previous limit of around 100 languages. They can also identify more than 4,000 spoken languages.
The company utilised publicly available audio recordings of religious texts, particularly the New Testament, which provided an average of 32 hours of data per language to gather data for such a vast number of languages.
Meta's objective is to further extend the reach of MMS models, allowing them to accommodate a wider range of languages and overcome the obstacles associated with dialects, a current hurdle in speech technology. By open-sourcing its models and code, the tech giant stated that it intends to encourage collaboration from the research community to preserve languages and foster global connectivity.
 Tags quentes :
Acesso digital
Diversidade cultural
Tags quentes :
Acesso digital
Diversidade cultural
Cadastre-se agora para Ações Semanais de Promoção
100% free, Unsubscribe any time!
Add 1: Room 605 6/F FA YUEN Commercial Building, 75-77 FA YUEN Street, Mongkok KL, HongKong Add 2: Room 405, Building E, MeiDu Building, Gong Shu District, Hangzhou City, Zhejiang Province, China
Whatsapp/Tel: +8618057156223 Tel: 0086 571 86729517 Tel em HK: 00852 66181601
Email: [email protected]
 English
English Pусский
Pусский Français
Français Español
Español Português
Português

