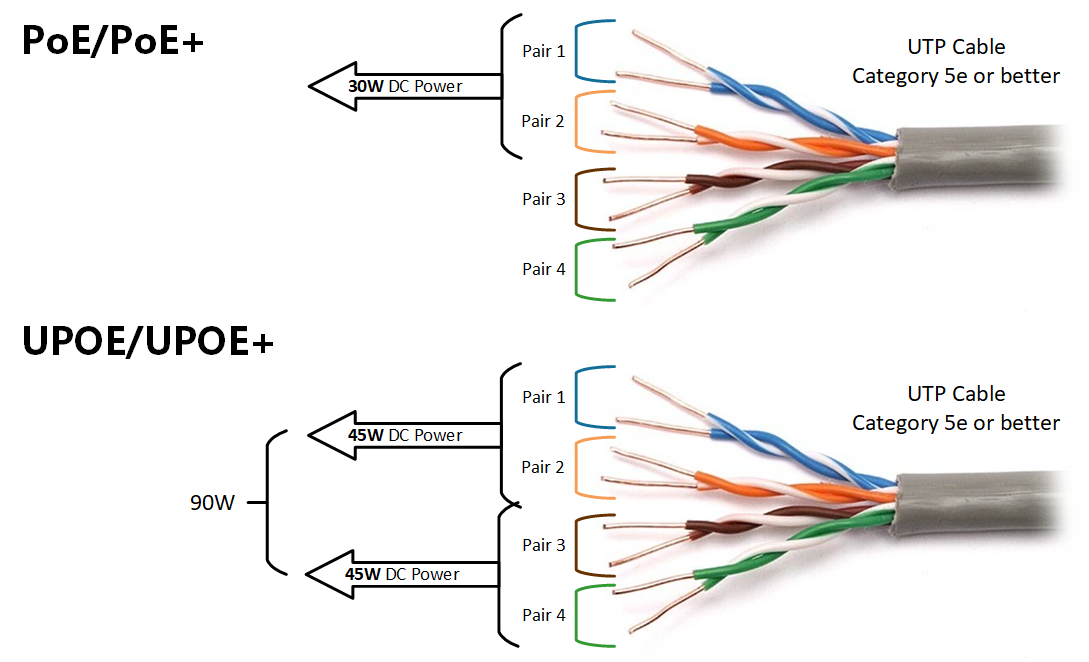
Cadastre-se agora para um orçamento mais personalizado!




























The so-called multi-view is a way of linking two different signals by considering the information they share about the same object despite differences. Multi-view may open a path to machines that can have a richer sense of the structure of the world, perhaps contributing to the goal of machines that can "reason" and "plan."
Tiernan Ray and DALL*E, ""Framed portraits of multiple views of an apple"Artificial intelligence in its most successful form -- things like ChatGPT or DeepMind's AlphaFold to predict proteins -- has been trapped in one conspicuously narrow dimension: The AI sees things from only one side, as a word, as an image, as a coordinate in space -- as any type of data, but only one at a time.
In very short order, neural networks are about to expand dramatically with a fusion of data forms that will look at life from many sides. It's an important development, for it may give neural networks greater grounding in the ways that the world coheres, the ways that things hold together, which could be an important stage in the movement toward programs that can one day perform what you would call "reasoning" and "planning" about the world.
Also: Meta unveils 'Seamless' speech-to-speech translator
The coming wave of multi-sided data has its roots in years of study by machine learning scientists, and generally goes by the name of "multi-view," or, alternately, data fusion. There's even an academic journal dedicated to the topic, called Information Fusion, published by scholarly publishing giant Elsevier.
Data fusion's profound idea is that anything in the world one is trying to examine has many sides to it at once. A web page, for example, has both the text you see with the naked eye, and the anchor text that links to that page, or even a third thing, the underlying HTML and CSS code that is the structure of the page.
An image of a person can have both a label for the person's name, and also the pixels of the image. A video has a frame of video but also the audio clip accompanying that frame.
Today's AI programs treat such varying data as separate pieces of information about the world, with little to no connection between them. Even when neural nets handle multiple kinds of data, such as text and audio, the most they do is process those data sets simultaneously -- they don't explicitly link multiple kinds of data with an understanding that they are views of the same object.
For example, Meta Properties -- owner of Facebook, Instagram, and WhatsApp -- on Tuesday unveiled its latest effort in machine translation, a tour de force in using multiple modalities of data. The program, SeamlessM4T, is trained on both speech data and text data at the same time, and can generate both text and audio for any task.
But SeamlessM4T doesn't perceive each unit of each signal as a facet of the same object.
Also:Meta's AI image generator says language may be all you need
That fractured view of things is beginning to change. In a paper published recently by New York University assistant professor and faculty fellow Ravid Shwartz-Ziv, and Meta's chief AI scientist, Yann LeCun, the duo discuss the goal of using multi-view to enrich deep learning neural networks by representing objects from multiple perspectives.
Objects are fractured into unrelated signals in today's deep neural networks. The coming wave of multi-modality, employing images plus sounds plus text plus point clouds, graph networks, and many other kinds of signals, may begin to put together a richer model of the structure of things.
Tiernan Ray and DALL*E, "An apple looking at its reflection in a large, square mirror with an elegant gilded frame."In the highly technical, and rather theoretical paper, posted on the arXiv pre-print server in April, Shwartz-Ziv and LeCun write that "the success of deep learning in various application domains has led to a growing interest in deep multiview methods, which have shown promising results."
Multi-view is heading toward a moment of destiny, as today's increasingly large neural networks -- such as SeamlessM4T -- take on more and more modalities, known as "multi-modal" AI.
Also: The best AI chatbots of 2023: ChatGPT and alternatives
The future of so-called generative AI, programs such as ChatGPT and Stable Diffusion, will combine a plethora of modalities into a single program, including not only text and images and video, but also point clouds and knowledge graphs, even bio-informatics data, and many more views of a scene or of an object.
The many different modalities offer potentially thousands of "views" of things, views that could contain mutual information, which could be a very rich approach to understanding the world. But it also raises challenges.
The key to multi-view in deep neural networks is a concept that Shwartz-Ziv and others have hypothesized known as an "information bottleneck." The information bottleneck becomes problematic as the number of modalities expands.
An information bottleneck is a key concept in machine learning. In the hidden layers of a deep network, the thinking goes, the input of the network is stripped down to those things most essential to output a reconstruction of the input, a form of compression and decompression.
Tiernan Ray and DALL*E, "glass bottle lying on its side, side view"+"multiple apples"+"green apple"+"and there is another apple made of green translucent glass to the right of the bottle"In an information bottleneck, multiple inputs are combined in a "representation" that extracts the salient details shared by the inputs as different views of the same object. In a second stage, that representation is then pared down to a compressed form that contains only the essential elements of the input necessary to predict an output that corresponds to that object. That process of amassing mutual information, and then stripping away or compressing all but the essentials, is the bottleneck of information.
The challenge for multi-view in large multi-modal networks is how to know what information from all the different views is essential for the many tasks that a giant neural net will perform with all those different modalities.
Also: You can build your own AI chatbot with this drag-and-drop tool
As a simple example, a neural network performing a text-based task such as ChatGPT, producing sentences of text, could break down when it has to also, say, produce images, if the details relevant for the latter task have been discarded during the compression stage.
As Shwartz-Ziv and LeCun write, "[S]eparating information into relevant and irrelevant components becomes challenging, often leading to suboptimal performance."
There's no clear answer yet to this problem, the scholars declare. It will require further research; in particular, redefining the multi-view from something that includes only two different views of an object to possibly many views.
"To ensure the optimality of this objective, we must expand the multiview assumption to include more than two views," they write. In particular, the traditional approach to multi-view assumes "that relevant information is shared among all different views and tasks, which might be overly restrictive," they add. It might be that views share only some information in some contexts.
Also: This is how generative AI will change the gig economy for the better
"As a result," they conclude, "defining and analyzing a more refined version of this naive solution is essential."
No doubt, the rise of multi-modality will push the science of multi-view to devise new solutions. The explosion of multi-modality in practice will lead to new theoretical breakthroughs for AI.
 Tags quentes :
Inteligência artificial
Inovação
Tags quentes :
Inteligência artificial
Inovação
Cadastre-se agora para Ações Semanais de Promoção
100% free, Unsubscribe any time!
Add 1: Room 605 6/F FA YUEN Commercial Building, 75-77 FA YUEN Street, Mongkok KL, HongKong Add 2: Room 405, Building E, MeiDu Building, Gong Shu District, Hangzhou City, Zhejiang Province, China
Whatsapp/Tel: +8618057156223 Tel: 0086 571 86729517 Tel em HK: 00852 66181601
Email: [email protected]
 English
English Pусский
Pусский Français
Français Español
Español Português
Português

