Cadastre-se agora para um orçamento mais personalizado!






























We went to Austin for BBQ,and an OpenStack Summit broke out...
...OK, maybe that's not entirely true, but the BBQ was good.
When we started this journey less than 5 weeks ago in preparation for the Austin OpenStack Summit, we'd already collectively had many OpenStack deployments under our belts, both manually deployedandthrough the use of automation, for example through the use of automation tools like Ansible. We went from days and weeks to deploy, down to hours. We experienced a lot of pain each time, even as we'd done our Nth deployment. But we somehow felt that, even with automation, it was not good enough. Some capabilities were still missing from the final product.
With CI/CD so pervasive now, coupled with DevOps, we thought that there must be a better, faster way to commoditize the spin up of an OpenStack cloud. In other words, could we make it available to the masses. To plot our course, we needed a vision of what a good deployment might look like.
So what was our vision when we talk about the OpenStack control plane? Ideally, it would have some of the following characteristics:
The focus of this blog post is to give attention to addressing a solution that isEasily Deployed, Quickly Operationalized, beConsistent and Repeatable across DevOps, and finally,Self-Healed, with our primary focus on availability.
Pain is a great motivator, and as previously mentioned, we experienced a lot of it during our deployments of OpenStack. Here are three areas where we've experienced some pain, which were key motivators driving our thoughts.
Deployment
Everybody wants it fast (or yesterday)!! When we talk about "fast", it's usually synonymous with automation. And furthermore, most people would agree that automation is table stakes in DevOps. Some automation tools are now available using Ansible, Chef, Puppet, etc. These have emerged to aid and speed deployment, some of which a few OpenStack projects utilize (e.g., Kolla). But these have the appearance of being adjunct to the core of OpenStack, and are still time consuming to setup.
Despite improvements in OpenStack documentation, they are still targeted to more of a generalized deployment approach, with indications of what knobs to tweak for added flexibility. And while OpenStack is quite flexible, it is this flexibility that organizations struggle to overcome when adapting to their deployment architecture. Enterprises are left with a "do it yourself" approach or utilizing one of many vendor turn-key solutions.
Inconsistencies in build and deployment environments
What worked last week no longer works this week!!!! Differing dependencies between development, staging and production environments can lead to breakage at any point along the way (e.g., packages, libraries, operating systems distros, kernel version). Some of this may be attributable to complicated organizational processes, which tend to have many moving parts, with many points of failure and opportunities for miscommunication.
Operationalization
First off, we need to engineer what our system should be capable of handling. That is, what is the appropriate scale, or how big should we make it to meet our anticipated demand? This capacity planning and scale testing adds significant, up-front man-hours, which can delay time-to-market. And yet, even with such planning, systems still tend to be over-provisioned because no one really knows what demand will be. Furthermore, when additional capacity is needed, expanding a system may result in more capacity than needed. We then must "stitch in" that added capacity into our system. Of course, the other side of this coin is that added capacity is not always removed when it's no longer needed, leaving excess capacity stranded. So by having elasticity, we could spend less time with up-front engineering, moving quickly to service deployment, allowing an auto-scaling system to handle elasticity around our pre-determined policies.
When we talk about operationalization, traditional monitoring tools are not enough anymore; they are more reactive than proactive. We need more advanced tools to collect additional metrics (e.g., U-S-E), metrics that trigger failovers or adapt scale based on demands. Such metrics can also provide teams with solid feedback on where adjustments may be needed. Of course, it is desirable that some of the metrics collected are tied to business outcomes. For example, latency tied to user experience, because after all, isn't user experience what it's all about anyway? But every coin has two sides. More advanced tooling requires specialized engineering skills to standup and monitor.
As we've stated in our vision, our primary focus is service availability first, and failure cause is secondary. We also lack built-in service healing without utilizing overlay automation. Again, self-healing should be the desired end-game, with our attention placed on service availability and, where finding the cause of failures, should be secondary.
Traditional OpenStack Control Plane Design
So what makes up an HA control plane, and where do some of our pain points manifest? We know that the goals of an HA control plane design are to eliminate single points of failure. We have multiple compute instances, of course. We lay in our networking and controllers, replicate as needed, and glue it altogether using tools like keepalived and load-balancers. Finally, we throw in some fixed scaling decisions, and, viola!!, we have our HA stack.

In its traditional form, this type of design has some pain points. Generally, when a service is created, expanded, or contracted, the load-balancing function must be updated to reflect the changes in the service. This can be a tedious, error-prone, manual process, or may require an overlay of orchestration to complete. We'd prefer if these load-balancing updates are handled behind the scenes, without our intervention.
Control plane components are HA as we note, were the redundant services are distributed across various controller instances. This works well under optimal conditions, such as, where demand is at or near "engineered" levels or under single fault conditions. But when a fault occurs, HA may be lost on multiple services because those replicated services tend to be bunched together. With demand at or near engineered levels, this may be tolerable. But under higher load, perhaps not so much. Moreover, we may invest several man-hours trying to determine where the failure cause lies. We'd like to have a self-healing control plane, and know with confidence that a service would function with maximum availability.
When we build out a traditional control plane, we tend to take our best-guess estimate, or even utilize some empirical data, to predict anticipated demand. While imperfect, it can lead to over or under-engineered systems. These issues may manifest as poor user experience (e.g., due to high latencies) or underutilized capacity. Over-utilization results in either a rebuild to expand capacity or requires additional nodes. This may then lead to idle / unused capacity during low demand periods. It becomes challenging to find the right balance, and operationally it becomes onerous to manage. It became clear that we'd much rather prefer if our system can scale up or down to meet demand, operating within a minimum or maximum range, with workloads placed when and where needed.
Enter Kubernetes: A light in a sea of darkness
When considering the key aspects of our Vision mentioned previously, we think about many of Kubernetes' attributes, and the attributes of containers in general, and how these can accommodate many of our needs. Let's quickly review some of those.
Kubernetes' advantages
Why Kubernetes has value in an OpenStack control plane
Some of the nicest features about Kubernetes, and why it gets our attention, is its self-healing attributes; namely, auto-restart, auto-scale, auto-replication. Those are features that are needed now, not tomorrow.
It's consistent with your build and your resources. You pragmatically and efficiently use only the resources you need...on demand.
It has built-in API health checks (specifically, application- or service-centric health checking) as well as the afore-mentioned self-healing services help lead to greater uptime of services. And more up-time is always a good thing, right?
Redesigning our OpenStack control plane
Reviewing our previously discussed HA control plane architecture, and then updating it with the proposed architecture, we replace the HAProxy instances with kube-proxy. Each service is built out separately, and managed and monitored via Kubernetes. We achieve failover by having multiple copies of each service, that we scale up or down based off of need. The load balancing that we found to be tedious to update with HAProxy, is updated in unison, without the need to reconfigure manually or through a separate layer of automation.
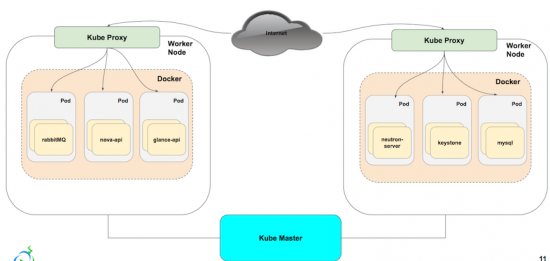
The architecture looks similar to the tradition HA control plane from an exposed service perspective, but in the next section you'll see how we've built, scaled, and monitored our control plane within Kubernetes.
Self Healed OpenStack Control Plane

Provisioning and Orchestration
What we like about Kubernetes is that it's a complete, automated container platform. With it, we can have a fully functional, self-healed control plane in about than 5 mins, thus spending less time on the installation/configuration and more time customizing it to fit our needs. It's also easier to provision and orchestrate new or existing applications, as pods can start in seconds versus the minutes it takes VMs to startup. Finally, it allows us to eliminate the need to worry about over/under provisioning, reducing the time needed for additional capacity planning.
CI/CD Consistency
First off, it's easy to deploy and maintain applications. Since Kubernetes leverages Docker as the build and deployment artifact, we gain a portable and sharable package in which a company can deploy their software to almost any infrastructure stack. Anyone who can build a Dockerfile can build a replicated service application in Kubernetes.
We also like that Kubernetes provides fully-integrated deployment options like rolling updates (for version or security purposes as an example), greenfield/brownfield deployments, and A/B testing. We found upgrading to no longer be a disruptive procedure, but a productive one.
Scaling
Benefit of the Kube-Service is its ability to maintain connectivity to the the underlying service aggregation even when it is rescheduled to a different node after failing and/or if the Pod's IP address changes. A key benefit for us is that it wasn't a necessary to spend additional time to reconfigure a load balancer due to change....Kubernetes does it for you.
We also like that there's significant cost reduction by increasing your average server utilization rate and therefore reducing your server footprint. Many environments run their VM's with a low utilization rate (sometimes as low as 10%) while applications in a Kubernetes cluster can see a much higher utilization rate (often as high as 70%).
Self-healing
Kubernetes has built in self-healing mechanisms, such as auto-restarting, re-scheduling, and replicating containers. As a user, you just define the state and Kubernetes ensures that the state is met at all times on the cluster. We've all had issues troubleshooting OpenStack services, whether it's in the pre-build architecture or post build service failure. With the ability to maintain service uptime, you replace the "what happened?" with "well, it self-corrected."
I'd like to reiterate the point that **maximizing service availability should always take priority** to finding the cause of failure. Not to ignore the cause, but up-time is king to maintaining any guarantees on your SLA.
OpenStack deployment can be easy and fast
With manual installation/configurations of the ancient age, we talked about days of work to bring up an OpenStack cluster with tons of "Layer 8 errors" and months chaos. With the advent of automation tools such as Ansible, we brought it down to hours; however, that was still not good enough. As we demonstrated at the Austin OpenStack Summit, it is possible to have a fully-automated approach to having a functional, self-healed OpenStack control plane in 5 mins. For our friends in Service team and Q/A team, we would love to hand it over to you so you can spend less time on installation/configuration, and MORE time to make your customer happy, or develop/execute automated test suite to ensure the code is always in deployable state.
CI/CD is quite feasible
Throughout the cycle of Continuous Integration, Continuous Delivery, Continuous Deployment, we anticipate small batch sizes of work flowing through Dev, to Q/A, to Operation teams. The original thinking is to dramatically increase the productivity by creating an environment on demand, limiting WIF, and build a system which is safe to change. However, in reality, quite often that is not the case. It causes more delay due to inconsistency between Development environment (for unit and functional testing), and Staging environment (to test business logic, find design issues and corner cases in the scale testing), and Production environment, which is the counter to the ultimate goals for any business. Given the nature of container to packaging your apps and its dependencies such as library and binaries, we can create a virtual isolation on top of your physical servers to avoid the conflicts; Don't forget that Kubernetes provides lifecycle management, so creating an env on demand is quite feasible. When your Developers needs an env, we can bring it up in secs; When she doesn't need it, we can remove it within secs. It's never been so easy before.
Operations will become more challenging...but still achievable
For our friends from the Operation teams, please don't feel that you are being left out. With all of this good news for the Dev, Q/A teams, we have a bit of bad news for you. When you get paged 2 in the morning, you may already have felt the pain of OpenStack control plane. Now with at least three replicas, the complexity level is at least multiplied by 3. To make the matters worse, the container names can be changed due to self-healing and the number of containers can be quite dynamic triggered by autoscaling; Considering the 10+ deployments every day, the complexity level will be exponential. However, we firmly believe a solid operational solution is still achievable, and perhaps, we can make this the talk of a future post.
It is all about improving efficiency
For the Decision Makers, we can summarize this article in one word:EFFICIENCY. It is all about improving the efficiency (sales and sales velocity), isn't it? What has been discussed is a new way of applying a technology, developed outside of OpenStack community, onto the OpenStack cloud itself. The business value is quite obvious. It drives down the cost and increases the usability of your OpenStack cloud by a significant factor. If you are willing to shift cost-performance curve even further, then join us in Barcelona and we will show you more.
Check out our session at OpenStack Summit!
A special thanks to Derek Chamorro, Shixiong Shang who were both extremely instrumental in pulling this entire effort together.
 Tags quentes :
OpenStack
containers
Kubernetes
docker
cloud orchestration
Tags quentes :
OpenStack
containers
Kubernetes
docker
cloud orchestration
Cadastre-se agora para Ações Semanais de Promoção
100% free, Unsubscribe any time!
Add 1: Room 605 6/F FA YUEN Commercial Building, 75-77 FA YUEN Street, Mongkok KL, HongKong Add 2: Room 405, Building E, MeiDu Building, Gong Shu District, Hangzhou City, Zhejiang Province, China
Whatsapp/Tel: +8618057156223 Tel: 0086 571 86729517 Tel em HK: 00852 66181601
Email: [email protected]
 English
English Pусский
Pусский Français
Français Español
Español Português
Português

