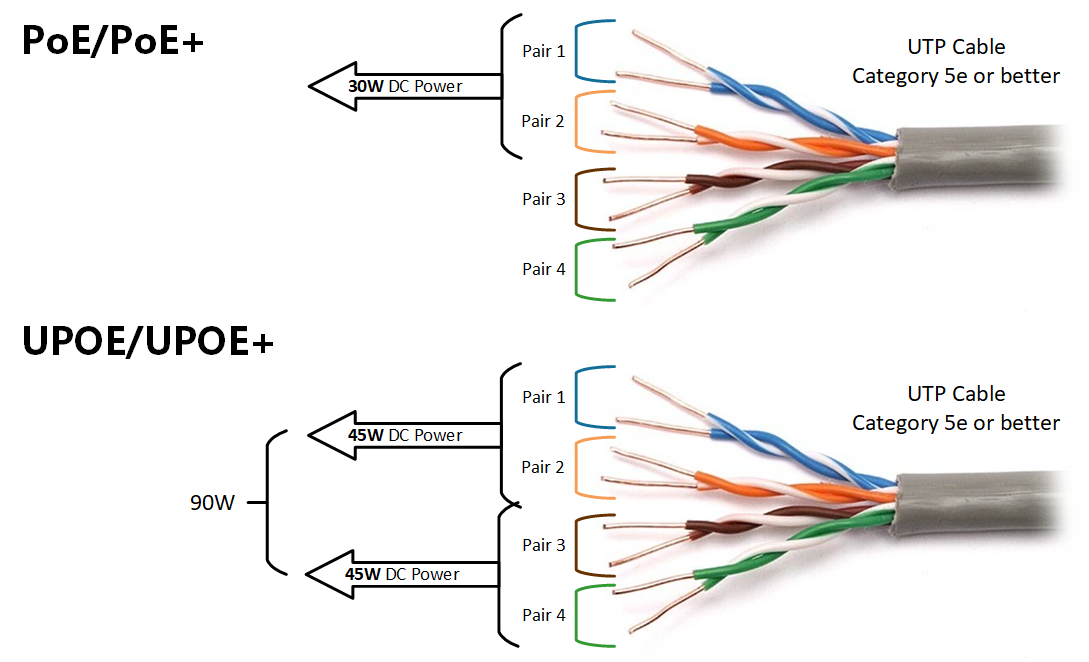
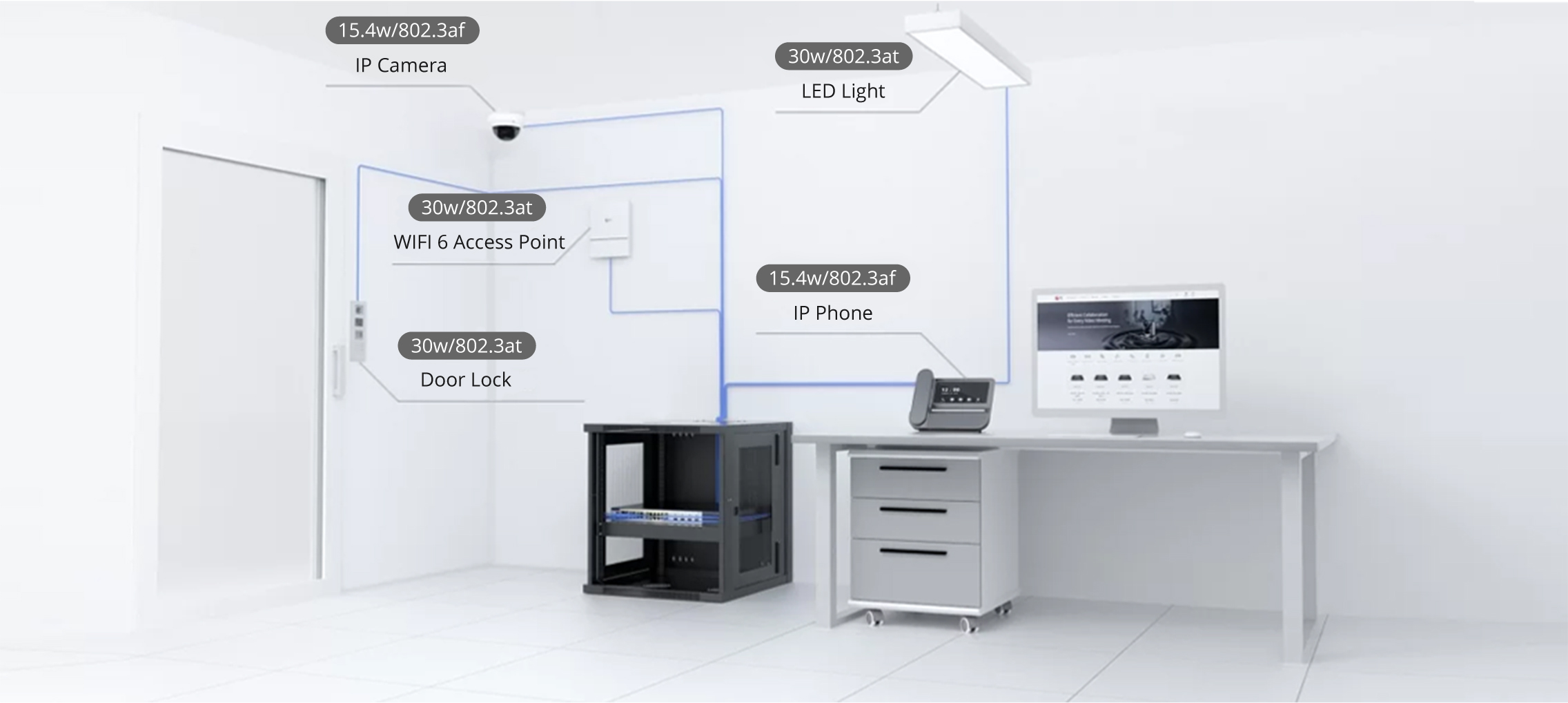
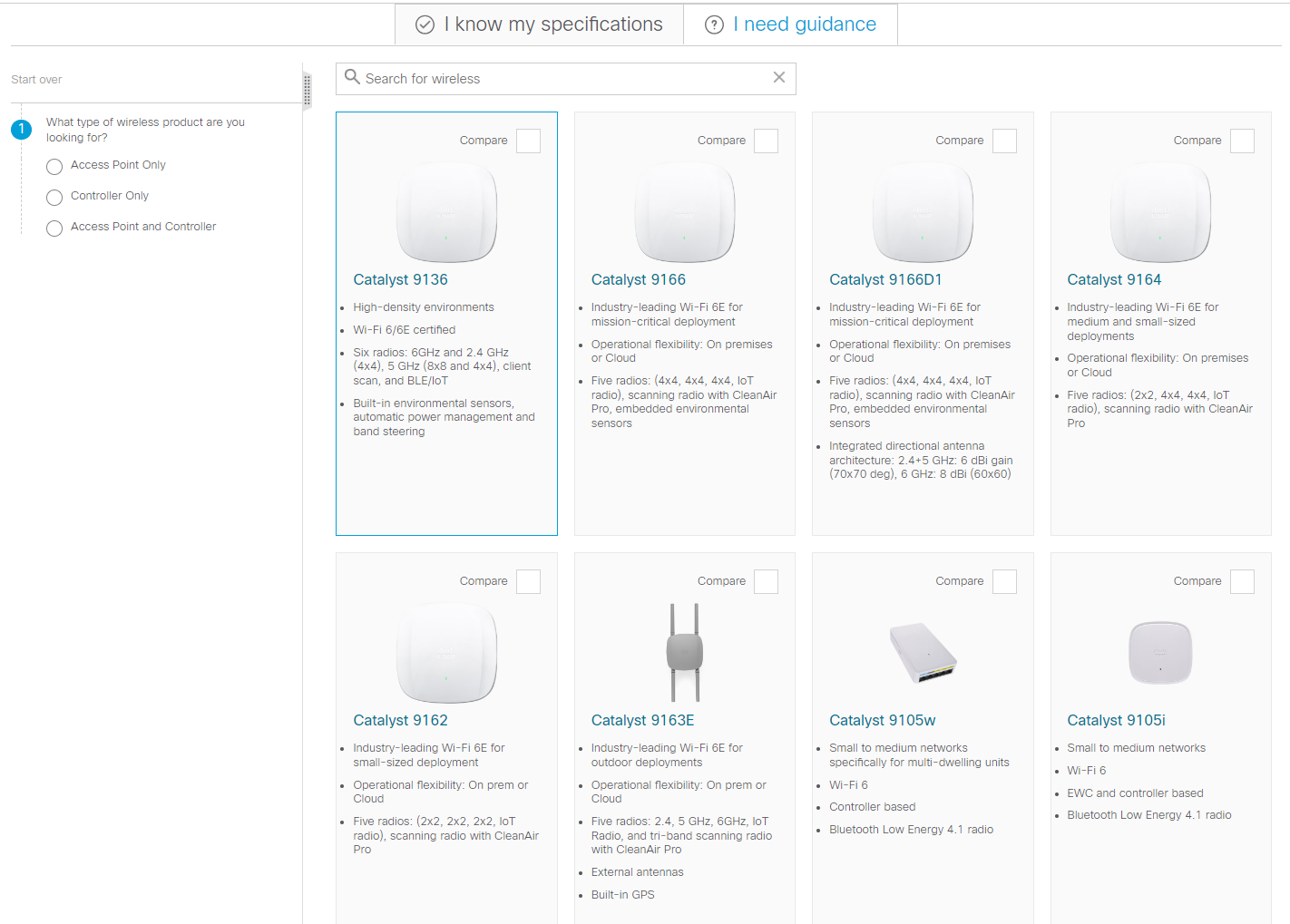
Cadastre-se agora para um orçamento mais personalizado!





















 Google
Google When Google artificial intelligence scientists revealed a significant new program -- the Pathways Language Model (PaLM) -- a year ago, they spent several hundred words in a technical paper describing the significant new AI techniques used to achieve the program's results.
Also: How to use ChatGPT: Everything you need to know
Introducing the successor to PaLM last week, PaLM 2, Google revealed almost nothing. In a single table entry tucked into an appendix at the back of the 92-page "Technical Report", Google scholars describe very briefly how, this time around, they won't be telling the world anything:
PaLM-2 is a new state-of-the-art language model. We have small, medium, and large variants that use stacked layers based on the Transformer architecture, with varying parameters depending on model size. Further details of model size and architecture are withheld from external publication.
The deliberate refusal to disclose the so-called architecture of PaLM 2 -- the way the program is constructed -- is at variance not only with the prior PaLM paper but is a distinct pivot from the entire history of AI publishing, which has been mostly based on open-source software code, and which has customarily included substantial details about program architecture.
Also:Every major AI feature announced at Google I/O 2023
The pivot is clearly a response to one of Google's biggest competitors, OpenAI, which stunned the research community in April when it refused to disclose details of its latest "generative AI" program, GPT-4. Distinguished scholars of AI warned the surprising choice by OpenAI could have a chilling effect on disclosure industry-wide, and the PaLM 2 paper is the first big sign they could be right.
(There is also a blog post summarizing the new elements of PaLM 2, but without technical detail.)
PaLM 2, like GPT-4, is a generative AI program that can produce clusters of text in response to prompts, allowing it to perform a number of tasks such as question answering and software coding.
Like OpenAI, Google is reversing course on decades of open publishing in AI research. It was a Google research paper in 2017, "Attention is all you need," that revealed in intimate detail a breakthrough program called The Transformer. That program was swiftly adopted by much of the AI research community, and by industry, to develop natural language processing programs.
Also:The best AI art generators to try
Among those offshoots is the ChatGPT program unveiled in the fall by OpenAI, the program that sparked global excitement over ChatGPT.
None of the authors of that original paper, including Ashish Vaswani, are listed among the PaLM 2 authors.
In a sense, then, by disclosing in its single paragraph that PaLM 2 is a descendent of The Transformer, and refusing to disclose anything else, the company's researchers are making clear both their contribution to the field and their intent to end that tradition of sharing breakthrough research.
The rest of the paper focuses on background about the training data used, and benchmark scores by which the program shines.
This materialdoesoffer a key insight, picking up on the research literature on AI: There is an ideal balance between the amount of data with which a machine learning program is trained and the size of the program.
Also:This new technology could blow away GPT-4 and everything like it
The authors were able to put the PaLM 2 program on a diet by finding the right balance of the program's size relative to the amount of training data, so that the program itself is far smaller than the original PaLM program, they write. That seems significant, given that the trend of AI has been in the opposite direction of late, to greater and greater scale.
As the authors write,
The largest model in the PaLM 2 family, PaLM 2-L, is significantly smaller than the largest PaLM model but uses more training compute. Our evaluation results show that PaLM 2 models significantly outperform PaLM on a variety of tasks, including natural language generation, translation, and reasoning. These results suggest that model scaling is not the only way to improve performance. Instead, performance can be unlocked by meticulous data selection and efficient architecture/objectives. Moreover, a smaller but higher quality model significantly improves inference efficiency, reduces serving cost, and enables the model's downstream application for more applications and users.
There is a sweet spot, the PaLM 2 authors are saying, between the balance of program size and training data amount. The PaLM 2 programs compared to PaLM show marked improvement in accuracy on benchmark tests, as the authors outline in a single table:
In that way, they are building on observations of the past two years of practical research in the scale of AI programs.
For example, a widely cited work by Jordan Hoffman and colleagues last year at Google's DeepMind coined what's come to be known as the Chinchilla rule of thumb, which is the formula for how to balance the amount of training data and the size of the program.
Also: Generative AI brings new risks to everyone. Here's how you can stay safe
The PaLM 2 scientists come up with slightly different numbers from Hoffman and team, but it validates what that paper had said. They show their results head-to-head with the Chinchilla work in a single table of scaling:
That insight is in keeping with efforts by young companies such as Snorkel, a three-year-old AI startup based in San Francisco, which in November unveiled tools for labeling training data. The premise of Snorkel is that better curation of data can reduce some of the compute that needs to happen.
This focus on a sweet spot is a bit of a departure from the original PaLM. With that model, Google emphasized the scale of training the program, noting it was "the largest TPU-based system configuration used for training to date," referring to Google's TPU computer chips.
Also: These 4 popular Microsoft apps are getting a big AI boost
No such boasts are made this time around. As little as is revealed in the new PaLM 2 work, you could say it does confirm the trend away from size for the sake of size, and toward a more thoughtful treatment of scale and ability.
 Tags quentes :
Inteligência artificial
Inovação
Tags quentes :
Inteligência artificial
Inovação
Cadastre-se agora para Ações Semanais de Promoção
100% free, Unsubscribe any time!
Add 1: Room 605 6/F FA YUEN Commercial Building, 75-77 FA YUEN Street, Mongkok KL, HongKong Add 2: Room 405, Building E, MeiDu Building, Gong Shu District, Hangzhou City, Zhejiang Province, China
Whatsapp/Tel: +8618057156223 Tel: 0086 571 86729517 Tel em HK: 00852 66181601
Email: [email protected]
 English
English Pусский
Pусский Français
Français Español
Español Português
Português

