Cadastre-se agora para um orçamento mais personalizado!































It may sound strange to hearmesay it, but when I wrote the previous blog post about Dynamic FCoE I thought that it may get a little blip of attention and then filed away as a "oh, that is cool" little factoid about Cisco's storage portfolio. Perhaps I shouldn't have been so nonchalant, but I confess I was not expecting the number of questions that I (and other speakers at CiscoLive back in May) have been getting about the technology.
Many questions -including some in the comments of the previous blog -have indicated a strong desire to know more, and they have been excellent and well-thought out. I'm going to try to address some of them in a deeper dive blog whenever I can, in the hopes of being able to address some of the concerns and clarify some points.
 We'll start with one of the biggest concerns -sharing the spine layer for logical separation of SAN A/B, and what happens if one of the spine switches (nodes) go offline.
We'll start with one of the biggest concerns -sharing the spine layer for logical separation of SAN A/B, and what happens if one of the spine switches (nodes) go offline.
One commenter from the previous blog, Pierre-Louis, asked the following excellent question:
How could we guarantee that's SCSI flows from one intiator [sic] to a specified target won't take exactly the same Spine in emulated Fabric A and B?
And if this was the case, what would be the impact (in terms of reading/writing) of a reboot/failure of this spine? If we consider that we have approximately 100ms of reconvergence, is there any "chance" that the server completely lose connectivity to its remote disks/datastrores?
If you don't happen to be a "storage guy/gal," this concern for losing connectivity may seem a bit unusual. After all, we have retransmit mechanisms inside of TCP that can help us in case of an error in the network. It is, however, an extremely fair question that deserves some major consideration.
In order to answer the question we have to take a step back and go a bit further into how Fibre Channel works on Cisco switches, especially when traversing Inter-Switch Links (ISLs).
When you join switches together to create an ISL, the Fibre Channel routing mechanism, called "Fabric Shortest Path First" (FSPF -almost no one spells it out any more) builds a routing table that is distributed to all of the switches. That routing table is a list of every possible path between any two domains in the fabric. FSPF then chooses the least costly path between any two switches, and all other possible paths are ignored for the time being.
If you use simple FSPF, the behavior is straight-forward, but limited. If you add a second link to this connection, then the paths are shared and are allocated on a round-robin basis. However, once you allocate a path to a device, all frames use that path even though another equal cost path can be available.
 Source-Destination ISLs
Source-Destination ISLs This is because FSPF doesnotload-balance across links -it only shares them. This can lead to one path being congested and another equal-cost path being underused.
This goes to the heart of Pierre-Louis' question. In this particular case, if a spine node like this were to go down -or worse if that node were shared by SAN AandB -Very Bad Things? can happen. Obviously, we do not want that to happen in any environment, regardless of whether it's Fibre Channel or Ethernet we're using.
By default, Cisco switches donotrely on basic FSPF forwarding. Instead, we use something called "exchange-based" load balancing (called "Source-Destination-Oiriginator Exchange", or "SRC/DST/OXID" for short). The reason for this is because it provides much better precision and balances that load and helps in precisely the situation that Pierre-Louis is talking about.
I hope you'll bear with me for a second as I explain this. You may have heard of "Buffer to buffer credits," which are used to make Fibre Channel a lossless networking protocol. Each "BB-Credit," as it's often referred to, corresponds to a frame that is sent across a wire.

What many people don't realize (or often remember), is that frames are not sent willy-nilly across the wire. Frames are based on SCSI Exchanges, which in turn are broken into sequences for retransmission purposes, and sequences are broken into frames for placing onto a wire.
Now, with all the talk about lossless storage traffic and in-order delivery, people tend to think that there is some sort of magic formula for making Fibre Channel work. The reality is that both SCSIandFibre Channel have mechanisms for recovery -they're just not based upon retransmitting individual frames.
When you send Fibre Channel from one place to another, you actually send fullexchangesand not just individual frames, and all frames in the same exchange follow the same link:
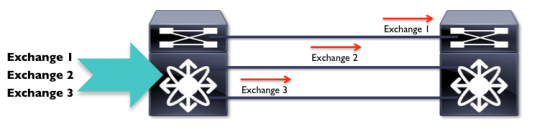 Source-Destination-OXID Load Balanced ISLs
Source-Destination-OXID Load Balanced ISLs Despite conventional wisdom, thereiserror-recovery mechanisms built into Fibre Channel, and they involve these sequences and exchanges. If an error occurs, a sequence retransmission (or exchange retransmission, depending on the error) is built into the FC standard. So, if a link goes down in this scenario, the exchange can be re-sent on the remaining available path(s).
With Dynamic FCoE and a properly configured FabricPath environment, all of the ISLs are equal-cost, and each exchange is sent in precisely the same fashion as in native Fibre Channel -the primary difference is that we are now using the FabricPath mechanism to provide the multipathing. Each spine represents one of the links in the total ISL capability upon which an Exchange is sent.
Think of this as exactly the same thing as a multi-link ISL between two switches (because, um, itisexactly the same thing):

Look familiar?
If so, that's because the only difference is that it's thearchitecturethat is providing the same kind of resilience and reliability that thelinksprovide in a traditional Fibre Channel (and/or FCoE) connection.
In this case, the SAN A sequence is sent out across the link based on the same SRC/DST/OXID method that Cisco uses forallFibre Channel-related traffic. If a link goes down, the exchange is retransmitted according to standard SCSI and Fibre Channel protocols.
What about SAN B?
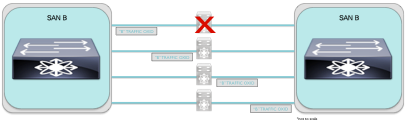
Once again, this should look familiar. If something goes wrong, and a link goes down, the exchange is retransmitted on an available equal-cost ISL link.
Now, let's overlap the two images so that we can see what happens to both SANs when a spine switch goes offline:

By this point you should see where I'm headed with this. Even though both SANs share the same spine link, standard FC rules still apply -for both SANs.
As long as you have more than one spine switch (which is explicitly stated in the configuration guides for Nexus 5500, 5600, and 6000 series as being required for having SAN A/B redundancy), then you are not sending all of the Fibre Channel traffic over one path. Youwon'thave the problems that would come up if we were using simple SRC/DST FSPF routing for our FC traffic, as described above.
The reconvergence times that Pierre-Louis refers to above that would occur in a typical FSPF recalculation do not affect the traffic patterns, then. In the case of a link-flap, or total switch failure, though, any exchanges in flight would trigger the normal exchange/sequence recovery mechanism built into FC in the first place -the exact same mechanism that is used in ISLs today on every Cisco Fibre Channel-capable device (including FCoE devices).
In short, we do not break the way that Fibre Channel works just in order to make it Dynamic. Hopefully this helps clarify some of the questions about how this technology works.
 Tags quentes :
FCoE
Fibre Channel
FabricPath
Load Balancing
Nexus 5600
Dynamic FCoE
Converged I/O
Clos architectures
Nexus 5500
Tags quentes :
FCoE
Fibre Channel
FabricPath
Load Balancing
Nexus 5600
Dynamic FCoE
Converged I/O
Clos architectures
Nexus 5500
Cadastre-se agora para Ações Semanais de Promoção
100% free, Unsubscribe any time!
Add 1: Room 605 6/F FA YUEN Commercial Building, 75-77 FA YUEN Street, Mongkok KL, HongKong Add 2: Room 405, Building E, MeiDu Building, Gong Shu District, Hangzhou City, Zhejiang Province, China
Whatsapp/Tel: +8618057156223 Tel: 0086 571 86729517 Tel em HK: 00852 66181601
Email: [email protected]
 English
English Pусский
Pусский Français
Français Español
Español Português
Português

