Cadastre-se agora para um orçamento mais personalizado!































The edge computing architecture comes with a variety of benefits. Placement of compute, storage, and network resources close to the location at which data is being generated typically improves response times and may reduce WAN based network traffic between an Edge site and central data center. This stated the distributed nature of edge site architectures also introduces several challenges related to data protection and disaster recovery. One requirement is performing local backups with the ability to conduct local recovery operations. Another formidable challenge involves edge site disaster recovery. Planning for the inevitable edge site outage, be it temporary, elongated, or permanent is the problem this blog takes a deeper look into.

Business continuity planning focuses on items such as Recovery Point Objective (RPO) and Recovery Time Objective (RTO). These measurements are generally expressed in terms of a Service Level Agreement (SLA). Under the covers exists a collection of infrastructure building blocks that make adherence to an SLA possible. In simplistic terms, the building blocks include the ability to perform backups, the ability to create additional copies of backups, provide a methodology to transport backup copies to remote locations (replication), an intuitive management interface, and connects to a preconfigured recovery infrastructure.
From an operational standpoint, an edge site disaster recovery solution includes workflows that enable the ability to:
Should an edge site failure or outage occur, workload failover to a disaster recovery site may become necessary. (Quite obviously, disaster recovery operations should be tested on an ongoing basis rather than just hoping things will work.) At the point where workload failover has been completed successfully, the failed over workload requires data protection. At the point where the edge site has been returned to an operational state, backup copies should be replicated back to the edge site. Alternatively, a new or different edge site may replace the original edge site. At some point, workload transition from the central site back to the edge site will occur.
Cohesity provides a number of DataProtect solutions to assist users in meeting data protection and disaster recovery business requirements. The Cohesity DataProtect product is available as a Virtual Edition and can be deployed as a single virtual machine hosted on a HyperFlex Edge cluster. A predefined small or large configuration is available for selection when the product is installed. The Cohesity DataProtect solution is also available in a ROBO Edition, running on a single Cisco UCS server.
Cohesity DataProtect edge solutions provide local protection of virtual machine workloads and can also replicate local backups to a larger centralized Cohesity cluster deployed on Cisco UCS servers.
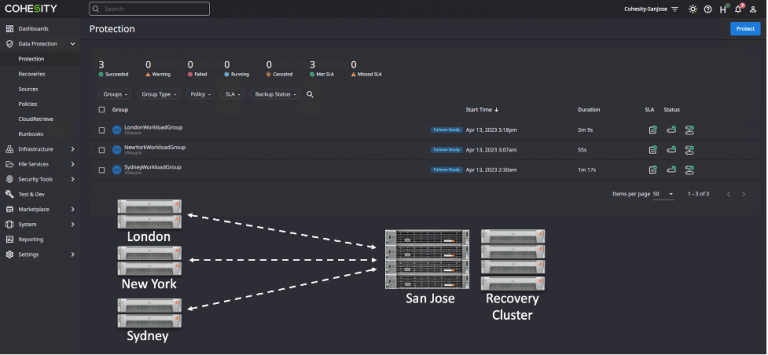
Cohesity protection groups are configured and define the workloads to protect. Protection groups also include a policy that defines the frequency and retention period for local backups. The policy also defines a replication destination, replication frequency, as well as the retention period for replicated backups.
In summary, Cisco HyperFlex with Cohesity DataProtect has built-in workflows that enable easy workload failover and failover testing. At the point where reverse replication can be initiated, a simple policy modification is all that is required. Cohesity also features Helios, a centralized management facility that enables the entire solution to be managed from a single web-based console.
For additional information about HyperFlex Solutions, please visit Cisco HyperFlex.
 Tags quentes :
#ciscodcc
Cisco HyperFlex
Cisco DCC
Cisco Data Center and Cloud
Cohesity
Cisco Data Protection
disaster recovery solutions
Tags quentes :
#ciscodcc
Cisco HyperFlex
Cisco DCC
Cisco Data Center and Cloud
Cohesity
Cisco Data Protection
disaster recovery solutions
Cadastre-se agora para Ações Semanais de Promoção
100% free, Unsubscribe any time!
Add 1: Room 605 6/F FA YUEN Commercial Building, 75-77 FA YUEN Street, Mongkok KL, HongKong Add 2: Room 405, Building E, MeiDu Building, Gong Shu District, Hangzhou City, Zhejiang Province, China
Whatsapp/Tel: +8618057156223 Tel: 0086 571 86729517 Tel em HK: 00852 66181601
Email: [email protected]
 English
English Pусский
Pусский Français
Français Español
Español Português
Português

